
A Cheap and Simple Way to Load Files on S3 to BigQuery using Cloud Composer
In this post, I would like to elaborate how I load my date-partitioned Parquet files on S3 to BigQuery using Airflow. I will explain how to do it as cheap as possible. I will also mention technical issue I met along the way so you can save your time. The Airflow being used is managed-service provided by Google Cloud Platform called Cloud Composer.
Aiflow to easily manage load tasks
My use case is to load tens or hundreds of tables worth of several years of data. Airflow makes it is easy to manage tasks with this complexity. I have experienced backfilling using ad hoc script in the past. Using ad hoc script was super hard and tedious to check which date the job failed, fix the issue, and rerun failed dates. Airflow makes it easy to check if my backfill is failed on certain date, I can easily view it on Airflow Dashboard, specifically on DAG’s Tree View. Failed tasks will have red color.
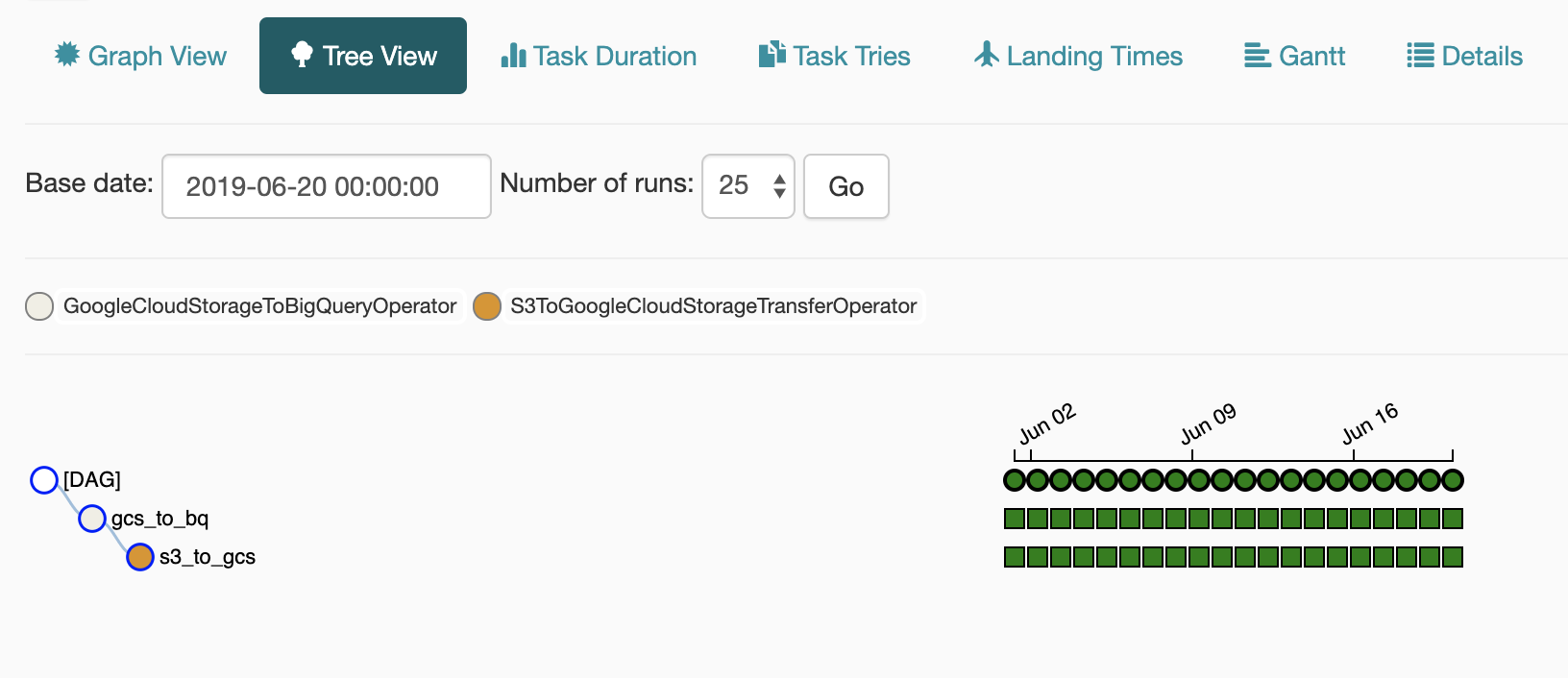
Transfer S3 files to GCS for Free
Now I know where my job will run, yet there are some alternatives to copy S3 files to GCS:
- Create a machine to download data from S3 and load to GCS
- Use big data processing such as Spark to read S3 and load to GCS
- Use Storage Transfer Service
The cheapest and easiest way to copy file as is is to use the third method, using Storage Transfer Service. It is cheaper because it is free! You don’t have to spawn any machines, so you will only incur AWS Out Data Transfer or egress. No cost on GCP beside storage cost. Based on several tries, it is quite fast and also very simple to use.
How the steps are tied together
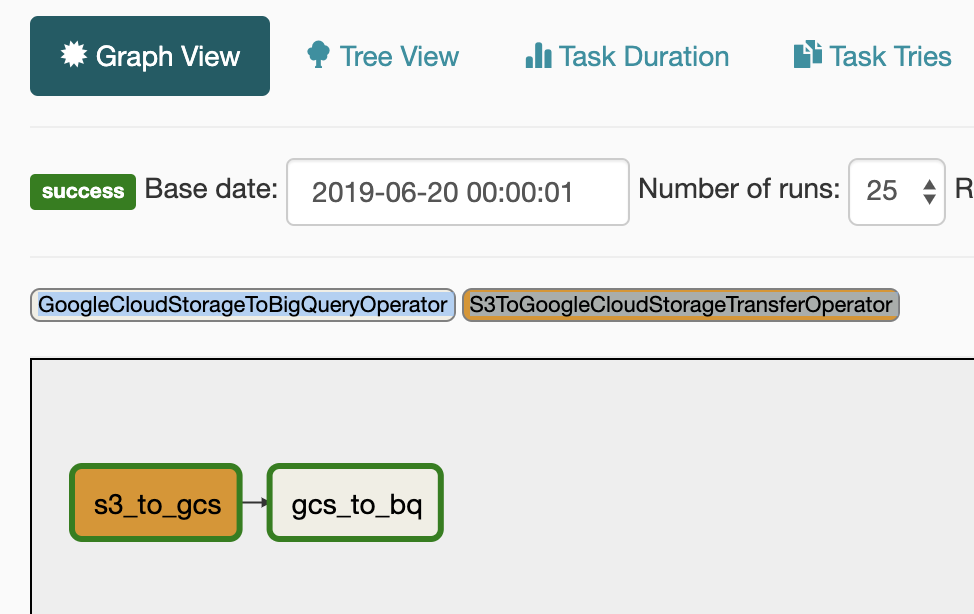
We are using airflow and Storage Transfer service. But how it fits the bigger picture? Here is the overall flow:
S3 --(Storage Transfer Service)--> GCS --(BQ Load)--> BigQuery
S3 Parquet files will be copied first to GCS. After it is copied completely to GCS, then the files are loaded to BigQuery. I am using S3ToGoogleCloudStorageTransferOperator operator to spawn Storage Transfer Service job. The task will keep waiting until the job finishes. After data loaded to GCS, I am using GoogleCloudStorageToBigQueryOperator operator to load data to BigQuery. The task create a BigQuery load job with specified parameters.
Handling Date-Partitioned Files
A bit more detail on handling date-partitioned files. To handle date-partitioned files, I am using airflow’s template variable such as ds.
# data partitioned by date
include_prefix = 'my_data/parquet/day_1/my_event/event_date={{ ds }}/part-'
# bq table partitioned by date
destination_table = 'my-gcp-project.mydataset.my_event${{ ds_nodash }}'
Variables above are being used to specify which S3 files to copy and to which BigQuery table partition to load. Here is how the variable is being used in S3 to GCS operator.
s3_to_gcs = S3ToGoogleCloudStorageTransferOperator(
...
object_conditions={ 'include_prefixes': [ include_prefix ] },
...
)
And here is how the variable is being used in GCS to BigQuery load operator.
gcs_to_bq = GoogleCloudStorageToBigQueryOperator(
...
source_objects=[ include_prefix + '*' ],
destination_project_dataset_table=destination_table,
...
)
Issues found during the implementation
The only issue I found was insufficient access for Storage Transfer Service to write to GCS. It was solved by adding a bucket policy which assign Storage Transfer’s service account a Storage Legacy Writer role. You can find the detail here https://cloud.google.com/storage-transfer/docs/configure-access#sink. It was not really clear when I read the storage transfer overview documentation.
Full code example
You can find example of the dag here https://github.com/rendybjunior/cloud-composer-examples
Feel free to comment if you have any issues on your implementation.



Leave a comment